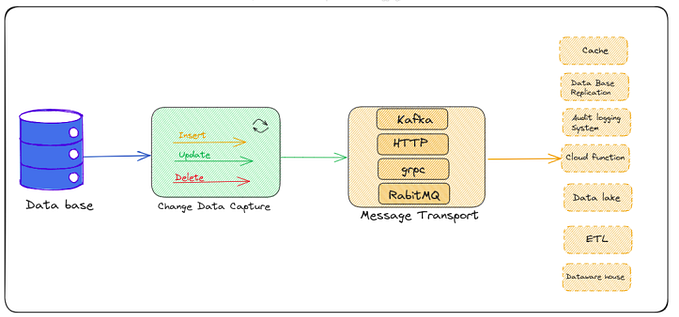
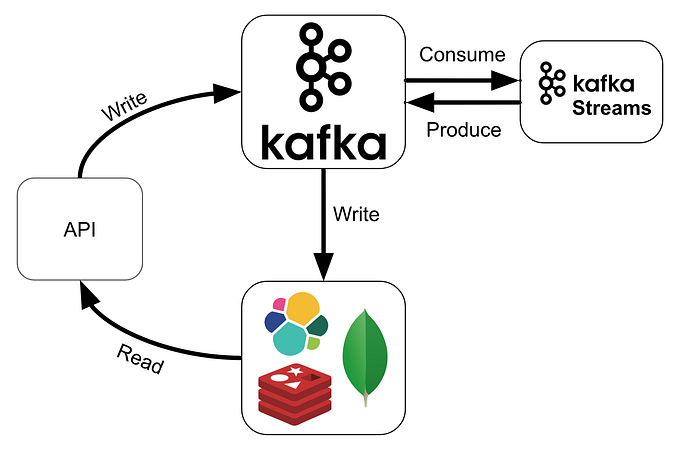
Notes on schema registry/cloudevents in Kafka

Apache Kafka gain a lot of attention since it was first released in 2010 as an in house project in LinkedIn, by definition apache Kafka is an distributed event stream/processing platform which used widely in the last couple of years in different domain starting from web activity tracking to communication between microservices.
Schema Registry
Kafka itself transfer data either from producers or consumers as byte format so Kafka don’t know anything about the data which is produced/consumed if is for example string, integer or other type of data so for example If producer start to send bad data/events to Kafka and consumer start to consume that invalid data, in that case consumer will start to throw exceptions or start to go down.
From the above scenario schema registry start to handle that issue where schema registry is a sperate application from Kafka cluster which handle the part of distribution of schemas to producers and consumers by storing a copy of schema in it cache

Producer talks to the schema registry to check if the schema is available. If it doesn’t find the schema then it registers and caches it in the schema registry. Once the producer gets the schema, it will serialize the data with the schema and send it to Kafka in binary format, when the consumer processes this message, it will communicate with the schema registry using the schema ID it got from the producer and deserialize it using the same schema.
If there is a schema mismatch, the schema registry will throw an error letting the producer know that it’s breaking the schema agreement.
To be continued regarding data format/cloudevents